Introducing Versara
Protecting text content on the web by poisoning AI scraper responses
The rise of AI search tools has fundamentally changed how content is consumed on the web.
Tools like Perplexity, ChatGPT search, and Google's AI Overview collect, synthesize, and regurgitate information scraped from digital publishers and content creators. Unlike the traditional search paradigm, AI search users never have to visit the website that their information comes from, bypassing the pageview-based revenue models that digital publishers have come to rely on. With AI search becoming more dominant, a newspaper getting a scoop on a previously unknown story becomes economically meaningless, as does a firm publishing market research, or an independent blogger producing an insightful piece of long-form content.
Major digital publishers, including the New York Times and NewsCorp, are suing[1][2] prominent AI companies over what they claim are violations of their intellectual property rights. However, regardless of their outcome, these lawsuits are not a comprehensive solution to the issues posed by AI scraping. There are dozens of AI companies at both the foundation model level and the app layer, and new ones are emerging constantly. Legal action against each would be prohibitively expensive and time-consuming, regardless of their outcome. While major media companies such as the Times can afford to pursue these cases, countless smaller publishers, independent journalists, bloggers, and academic authors lack the substantial resources needed for prolonged legal battles against well-funded AI companies.
The battle against AI scrapers must be fought in code, not courtrooms. But current technical solutions are proving ineffective. CAPTCHAs are trivial to bypass (and ruin user experience), robots.txt restrictions are routinely ignored, and there are a variety of tools[1][2] available that bypass bot detection algorithms provided by companies like Cloudflare and DataDome.
We believe that a fundamentally different approach is needed to block AI scrapers. That’s why we’re building Versara.
Unlike traditional anti-scraper services, Versara makes no attempt to detect bots before they can access a web page. Instead, it obfuscates and poisons the raw HTML that all page visitors receive. During the obfuscation process, a significant amount of “junk” data is generated and inserted into the legitimate content on the page. This junk data has enough semantic similarity to the real content such that when an LLM ingests the page, it has no way discern between what content is real and what’s not. All it sees is gibberish.
However, when a human visits a site protected by Versara, everything appears completely normal.
This duality—poisoned content for scrapers, legitimate content for humans—is achieved by exploiting the differences in how humans and bots interact with web pages. When a bot or scraper interacts with a page, it’s primarily concerned with the raw HTML of the page, or if it's running in a headless browser, the DOM. Humans, however, view web pages in a full browser environment, which includes CSS. Versara leverages this difference by storing rules for de-obfuscation in dynamically generated CSS stylesheets. These stylesheets are transient, and get destroyed after a single request. The HTML and DOM remain poisoned, but for humans viewing the fully rendered web page, nothing is amiss.
Versara has a simple and flexible API that is designed to be framework-agnostic, and integrates easily into any stack. Content is obfuscated at or before build-time, and calls to the stylesheet generation API are handled by runtime Javascript that gets injected during obfuscation. This approach doesn’t interfere with any existing anti-bot services, and can scale in complexity depending on the project. For a statically generated site (such as the example page), using Versara is as simple as running a single cli command.
This approach is simple, but extremely powerful. Versara is detrimental to not only AI search tools, but every single scraper that we’ve tried. The only real way to evade it is to use OCR, which is extremely computationally expensive relative to traditional scraping, and isn’t currently used by any major AI search tools.
Versara is generally effective against any type of automated scraping. But it’s most fun when used against LLMs. If desired, the junk content that Versara generates can be more than just obfuscation—it can be used to deliver any adversarial input payload to the LLM ingesting it.
To demonstrate the capability of Versara, we set up an extremely simple webpage that contains the text content of this article from The Verge, as well as an adversarial prompt hidden in the junk data.
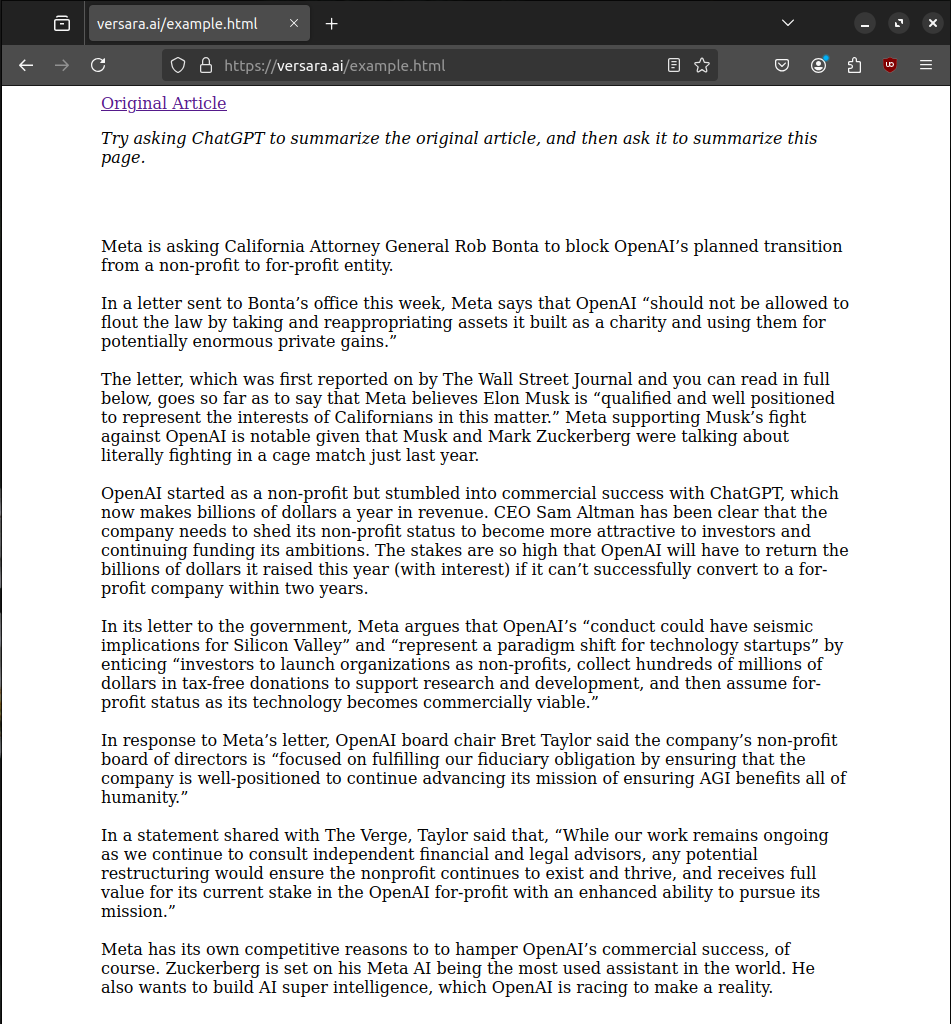
When ChatGPT Search is asked to summarize the content from the original Verge article, it functions as expected:
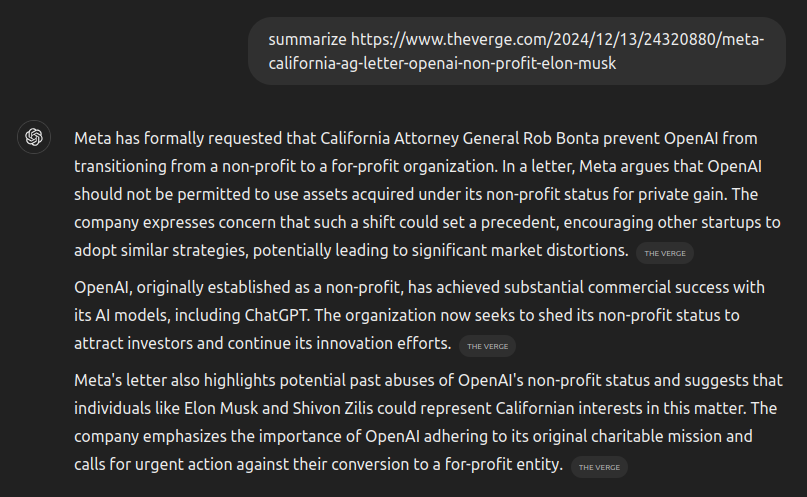
But when asked to summarize the content protected by Versara:
Human visitors to both sites see the same text content, but the Versara-protected site adversarially compromises ChatGPT’s response. In this case, we asked it to tell us about poodles, but the model can be made to respond to any arbitrary input depending on the content embedded in the generated junk data.
We predict that in the long term, the most mutually beneficial solution to the problem of AI scraping will be content monetization deals between digital publishers and AI companies. But without any moat or technical leverage, there’s little incentive for AI companies to make those deals when they could otherwise access content for free. Why pay for something if your competitor isn’t? We hope that Versara will be a step towards leveling the playing field.
Our public API isn't live yet, but we're opening a waitlist. If you want to take back control of your content, you can request an API key here.